Weather forecasters are already warning about an intense El Niño season that’s expected to alter precipitation levels and temperatures worldwide. El Niño seasons, characterized by warmer Pacific Ocean water along the equator, may impact the spread of some infectious diseases transmitted by mosquitoes.
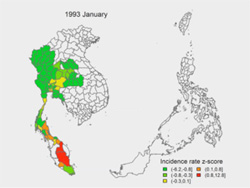
In a study published last month in the Proceedings of the National Academy of Sciences, researchers reported a link between intense dengue fever epidemics in Southeast Asia and the high temperatures that a previous El Niño weather event brought to that region.
Dengue fever, a viral infection transmitted by the Aedes mosquito, can cause life-threatening high fever, severe joint pain and bleeding. Infection rates soar every two to five years. Interested in understanding why, an international team of researchers collected and analyzed incidence reports including 3.5 million dengue fever cases across eight Southeast Asian countries spanning an 18-year period. The study is part of Project Tycho, an effort to study disease transmission dynamics by mining historical data and making that data freely available to others. Continue reading “El Niño Season Temperatures Linked to Dengue Epidemics”